Using nextflow for software pipelines

Banner created in canva.
So last time I posted about an anaconda environment to install data science-related software because I wanted to get into a work-related problem that I will describe. Here, at my workplace, we perform the analysis of sequencing data using the same software sequence. Usually, we have a GitHub where we post our scripts usually in bash language with all software sequences and parameters used. Not long ago, I went to a meeting with other bioinformaticians from my department who are spread around the country. One of them mentioned Nextflow, and how it could solve pipeline problems. The result is executing nextflow with all the parameters needed and it executes automatically everything that we need getting all the outputs that we want. After this meeting, I brought this to my supervisor and he decided to implement nextflow for our main DNA sequencing analysis pipeline. I and a co-worker started to work on the programming of the pipeline, which has a different logic and language that I wasn't used to.
Então, da última vez eu publiquei sobre um ambiente Anaconda para instalar softwares relacionados à ciência de dados, porque eu queria abordar um problema relacionado ao trabalho que irei descrever. Aqui, no meu local de trabalho, realizamos a análise de dados de sequenciamento usando o mesmo software de sequenciamento. Geralmente, temos um repositório no GitHub onde postamos nossos scripts, geralmente em linguagem Bash, com todas as sequências de software e parâmetros usados. Não faz muito tempo, participei de uma reunião com outros bioinformaticistas do meu departamento, que estão espalhados pelo país. Um deles mencionou o Nextflow e como ele poderia resolver problemas de pipeline. O resultado é que ao executar o Nextflow com todos os parâmetros necessários, ele executa automaticamente tudo o que precisamos, fornecendo todas as saídas desejadas. Após essa reunião, apresentei isso ao meu supervisor e ele decidiu implementar o Nextflow em nosso pipeline principal de análise de sequenciamento de DNA. Eu e um colega de trabalho começamos a trabalhar na programação do pipeline, que possui uma lógica e linguagem diferentes das que eu estava acostumado.
But what how does nextflow work? It works in a language called groovy which I have never heard about it before. This language is an extension of Java and has similar string functions found in Python for example. Essentially the script works with a structure called "processes" which are coded with the script that you want to run, it can be in bash or other scripts. A process has inputs ( which can be parameters that you enter, such as a software parameter or directory and/or file location) and outputs which are the results of a process. For example, the process below concatenate fastq files. The input is just folders and the output is the concatenated fastq file.
Mas como o Nextflow funciona? Ele funciona em uma linguagem chamada Groovy, que eu nunca tinha ouvido falar antes. Essa linguagem é uma extensão do Java e possui funções de strings similares às encontradas em Python, por exemplo. Essencialmente, o script trabalha com uma estrutura chamada "processos", que são codificados com o script que você deseja executar, podendo ser em bash ou outros scripts. Um processo possui entradas (que podem ser parâmetros que você insere, como um parâmetro de software ou localização de diretório e/ou arquivo) e saídas, que são os resultados de um processo. Por exemplo, o processo abaixo concatena arquivos fastq. A entrada são apenas pastas e a saída é o arquivo fastq concatenado.
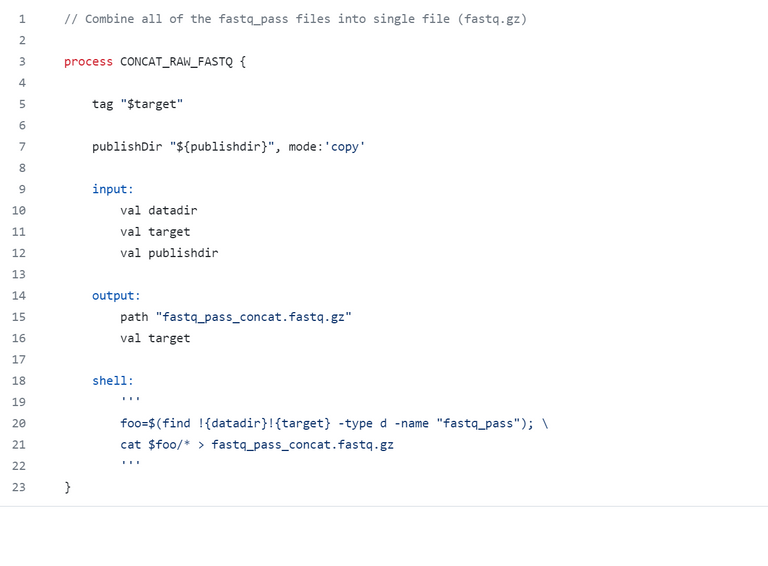
Example of a nextflow process from our pipeline.
The output of this process goes into what nextflow calls a "channel". Channels can be manipulated and used as input for new processes. We organized the processes in separate files which are called by a main file, similar to "functions". This main file has other attributes such as initial parameters which are stored using arguments in the command line. The example below shows the parameters for our nextflow main script, we added default values for all of them, but they can be changed in the command line.
A saída desse processo é direcionada para o que o Nextflow chama de "canal" (channel). Os canais podem ser manipulados e usados como entrada para novos processos. Organizamos os processos em arquivos separados, que são chamados por um arquivo principal, similar a "funções". Esse arquivo principal possui outros atributos, como parâmetros iniciais que são armazenados usando argumentos na linha de comando. O exemplo abaixo mostra os parâmetros para nosso script principal do Nextflow, onde adicionamos valores padrão para cada um deles, mas eles podem ser alterados na linha de comando.

Example of parameters declared.
In addition we need to include all processes that are going to be used in the pipeline and also their respective location, similar to functions again.
Além disso, precisamos incluir todos os processos que serão usados no pipeline, assim como suas respectivas localizações, novamente semelhante a funções.

Example of processes imported.
The next chunk of code is what is called the "workflow" where we add the sequence of processes. As you can see some processes are used as input. In addition, we decided to use one channel to perform output parsing without creating a process in "KRAKEN" output. There we used one of the outputs of this process and programmed a parsing chunk that can be used as input in another process.
A próxima parte do código é o que é chamado de "workflow", onde adicionamos a sequência de processos. Como você pode ver, alguns processos são usados como entrada. Além disso, decidimos usar um canal para realizar a análise de saída sem criar um processo no resultado do "KRAKEN". Nós utilizamos uma das saídas desse processo e programamos um trecho de análise que pode ser usado como entrada em outro processo.
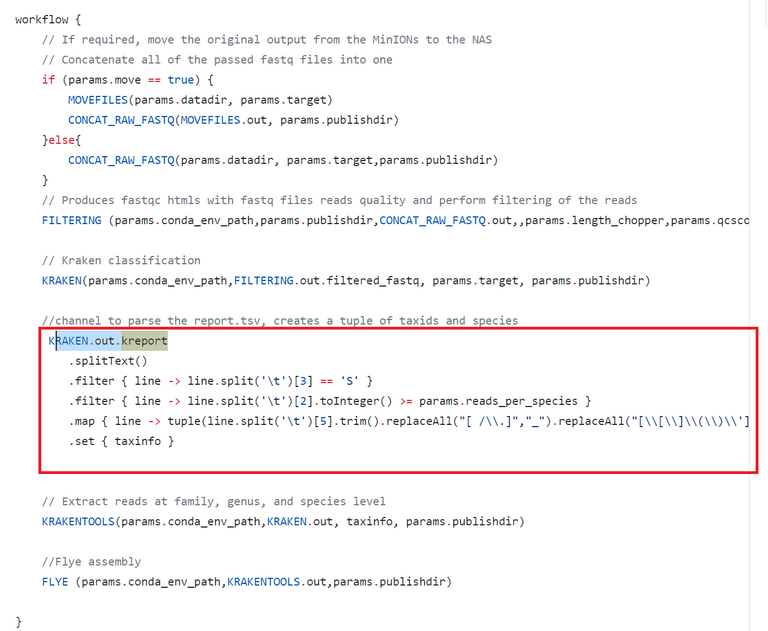
Workflow with sequence of processes, in the red rectangle you can find one channel parsing.
But why I cited my anaconda post? Most of the software used here they don't come in a regular Linux environment, so we need to install it. To avoid version differences we can add to the pipeline a YAML file with all versions of software files used and they can be loaded with a simple line in nextflow. This way we can have a dedicated conda environment that can be used by the script in any machine that downloads the script. Below you can find an example of a code to load the conda environment.
Mas por que mencionei minha postagem sobre o Anaconda? A maioria dos softwares usados aqui não está disponível em um ambiente Linux regular, então precisamos instalá-los. Para evitar diferenças de versão, podemos adicionar ao pipeline um arquivo YAML com todas as versões dos arquivos de software utilizados, e eles podem ser carregados com uma simples linha de código no Nextflow. Dessa forma, podemos ter um ambiente conda dedicado que pode ser usado pelo script em qualquer máquina que faça o download do script. Abaixo você pode encontrar um exemplo de código para carregar o ambiente conda.

A process that uses the software Kraken and the command in the black rectangle can use the conda environment which contains the software version that is necessary to run it.
In conclusion, nextflow is a simple solution for your pipelines which need a little bit of a learning curve to understand its logic mainly and get some practice with the groovy language. To install it, it is simple. Just download one single file and start creating your scripts to run with this single file called "nextflow". In this link in here you can find the getting started and how to install it and more tutorials. I hope this can help some of you.
Em conclusão, o Nextflow é uma solução simples para pipelines que requerem um pouco de aprendizado para entender sua lógica e ganhar prática com a linguagem Groovy. Para instalá-lo, é simples. Basta fazer o download de um único arquivo e começar a criar seus scripts para executar com esse arquivo chamado "nextflow". Neste link aqui, você pode encontrar um guia de introdução, informações sobre como instalar e mais tutoriais. Espero que isso possa ajudar alguns de vocês.
https://leofinance.io/threads/gwajnberg/re-leothreads-2pzeg546n
The rewards earned on this comment will go directly to the people ( gwajnberg ) sharing the post on LeoThreads,LikeTu,dBuzz.
Obrigado por promover a comunidade Hive-BR em suas postagens.
Vamos seguir fortalecendo a Hive
https://twitter.com/GabrielWajnberg/status/1667278268058198019?s=20
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.
Congratulations @gwajnberg! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 3500 replies.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPYay! 🤗
Your content has been boosted with Ecency Points, by @gwajnberg.
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more