Note to self: It is just an Api call
Some things are so basic and fundamental to web development that it can be surprising when someone is not all together clued up with them.
I do find myself often avoiding such areas, a prime example is Fetch() or basic HTTPS calls, really almost any kind of network, disc or database operation.

So it is not surprising that I do have a bit of a library dependence on things. Sure they simplify life but they also abstract the underlying operations.
Instead of having to then write
SELECT * FROM deadbeat_dads WHERE child="me"
in Laravel I can just write, and assuming only 1 child per Dad :P
DeadBeatDads::where('child','me')->get()
In Javascript land, there is a library for everything, even for things built into the language. Then you get node.js which is just a backend that runs on JS.
Why many like it is because now you have one language for both front and back, which I don't really think is completely the right way to think about it. You still have two different contexts and when working with SSR for example, that will bite you in the ass more often than not.
Needless to say, the context switch for me in Node and the different frontend frameworks like Nuxt can be super irritating.
Anyway now I am rambling.
Fetching data is fetch
Getting back on topic. One of the many things I avoid, or at least it feels like it. Is Fetch().
A while back it took me more time than I care to admit to do a simple Fetch() call from JS to one of the Hive RPCnodes ... Turns out you need to be posting data.
I finally figured out the required Json to be sending by looking at network calls made by Peakd, and I think Beeswap and proceeded to fail like a dumbass because I did not set it to be a POST.
Aside from that and some tips from @foxon I ended up with a pretty general-purpose template for all Hive calls using fetch...
The moment I want to build a botty whose only job is to get info and respond to said info, what do I do?
I reach for a library.
Now after some trial and error, I even read some docs. I am pretty sure I can say that @mahdiyari has it pretty much right with the https://github.com/mahdiyari/hive-tx-js library.
In my opinion a Hive library pretty much needs 4 things.
- Signing transactions because that is a nightmare
- Broadcasting said transactions
- Key validation / Encryption Helpers
- A retry and failover state for dealing with nodes
Everything else can pretty much just be helpers. Want to get a block range but be given all the comments only? Sure put that into the library.
Why did I use Dhive then?
It seems more approachable and it does have all the frontend functionality you might want. It is promise based, has these docs which are actually very helpful https://openhive-network.github.io/dhive/ and most chatter in discord when I do searches use Dhive as an example. Hive docs use it for their snippets.
And most naively it has a getBlocks() method :P
Remember the cover image? Yes the Hive Api call for fetching a bunch of blocks in one go is block_api.get_block_range and it is as simple as it gets, give it a start and a range. It will then return those blocks for you.
In my mind I am like that is nice, so proceeded to use the getBlocks() method in Dhive, very confident that this is the same thing, it even has smartness baked in where it knows when I am at the head and will just keep fetching as new blocks come in.

Obviously I am not the smartest cookie.
get_block_range or getBlocks()
The getBlocks method worked just fine, until I decided to get blocks from way way back to the current height. At first I figured oh it is probably fine, like it will speed up, sure 1-2 seconds a block is ok, it makes sense, oh look in production it is 0.5seconds - 2seconds, oh wow local is slow; yeah; ok that was 4 minutes for 100 blocks; that is in production; OK... WTF!!!!
Needless to say it never hit me what getBlocks is actually doing, and it should have since I know already that "streaming" on Hive means hit the endpoints BLAZINGLY fast until you get something new.
To be fair, I really don't know if get_block_range is new in the Hive API and unfortunately it has no usage policy aside from me asking say @deathwing if it is ok for me to hit his Node for 100 blocks at a time.
As mentioned local vs production and probably some other things affect the speed at which I get these blocks, but using the get_block_range call directly via Dhive's client.call() method will be in the range of 10x faster.
If only because you are not doing 100 handshakes.
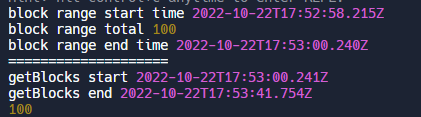
get_block_range = 2 seconds
getBlocks = 40 seconds
for 100 blocks
Fetching 100 blocks in this Repl I think shows the diff well enough and really network differences only increase the baselines.
Using getBlocks() to run a replay is pretty much the stupidest thing I could have done.
So for my usecase it will be a case of just having a toggle, if the code recognizes it is behind by say 100 or more blocks it should switch over to the get_block_range call and if it is pretty much in sync with the chain then go ahead and use the getBlocks method.
I would do that because getBlocks already handles a few things, such as also providing errors...
Get_block_range only returns an empty array if you are out of bounds, but then again if I need to be getting the headblock number anyway I can just always flatten the range and use get_block_range all the time or wait until I am 100 blocks behind.
I guess each to their own, but thinking of it now building a change over sounds like a problem also considering the flow of the code. Although depending what you are doing there might be a need for realtime data once caught up then changing from bulk to streaming is probably a good idea.
Anyhow, here is the code from the Repl above. It is as simple as can be expected from my ass, and probably still wrong but as stated in the title. Note to self.
import { Client } from "@hiveio/dhive";
const client = new Client(["https://api.hive.blog",
"https://api.deathwing.me","https://api.hivekings.com",
"https://anyx.io", "https://api.openhive.network"]);
const startBlock = 68990869
const range = 100
const getBlocksRange = range - 1
let blocks = []
//direct call
console.log('block range start time',new Date())
const getBlocks = await client.call('block_api','get_block_range',
{"starting_block_num": startBlock,
"count": range
})
// console.log(getBlocks)
console.log('block range total',getBlocks.blocks.length)
console.log('block range end time',new Date())
console.log('====================')
console.log('getBlocks start', new Date())
for await (const block of client.blockchain.getBlocks(
{ from: startBlock, to: startBlock + getBlocksRange })) {
blocks.push(block)
}
console.log('getBlocks end', new Date())
console.log(blocks.length)
https://twitter.com/32334844/status/1583888700106477568
The rewards earned on this comment will go directly to the people( @penderis ) sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
I'll confess that a lot of my read-only hive utility scripts use Fetch or Axios with no other library. It's just not worth the overhead for dhive sometimes.
But yeah, when I need to sign a txn. Yep, gimme a library.
My biggest hack is probably a Google sheet that constructs a JSON string from a couple of input cells then uses ImportJSON.gs to grab Hive-engine token data. I feel dirty and proud at the same time. Hey, but it's perfect for its user - he knows spreadsheets well.
Yeah, I think the more I deal with just needing to fetch data the biggest problem is knowing what inputs to put in, usually, a library has defined inputs it expects so I like that it will just tell me to input this and this parameter. When they require me to still structure the object myself then definitely it is probably just best to use fetch or axios and do it myself anyway.
I agree the sheets utility is actually impressive and really so many people just want to see the data in a nicely formatted way so either you spend hours building a output and for any change need to update code or you go the enlightened way and let sheets do what they do best and display that data for you with the power of then being able to transform it without getting bogged down in code at all. So that is probably a super user utility right there :) !PIZZA !LOLZ
You are funny 😆👏
And cool 👍
Thank :P

!PIZZA !LOLZ
lolztoken.com
I didn't even know they were catholic.
Credit: reddit
@nickydee, I sent you an $LOLZ on behalf of @penderis
Delegate Hive Tokens to Farm $LOLZ and earn 110% Rewards. Learn more.
(2/2)
Is it easy enough to pull data from the hive API with python?
Yes, I think fetching data is easy enough in any language you choose, it is just an
https postto a URL with the right parameters. Well I say easy enough, the parameters will be what can seem quite daunting for some calls but mostly straightforward except for actually broadcasting a transaction for that definitely you should use one of the libraries.https://developers.hive.io/resources/#resources-client-libs
thanks!
!PIZZA !LOLZ
Omg! I have always wanted to communicate with the Hive Blockchain via my code but I end up postponing reading the Hive dev documentation.
Thanks for this detailed post because I'm sure coming back to it.
However, I have always used fetch and I love it.
Yes you can definitely use fetch and I would say for any broadcasting use a library but if it is user facing you can let keychain handle all of that for you. The curl examples in the hivedocs do a good job of showing what is required except for all the general headers like cross-site , allow-origin and those kinds of HTTP headers. Remember to just have your ID on the jsonrpc call be dynamic so the calls don't overlap - honestly not sure what the damage is if you try two calls from same code with same ID , I forget the error but all in all, it is no diff from a normal API call for the most part. Goodluck !PIZZA !LOLZ
One of the reasons to use Dhive is for its TypeScript typings. If you're just writing vanilla Javascript, then it probably doesn't matter. But, for me, the definitions for the Dhive functions and return values can avoid a trip to the docs to understand how something works.
I do like that it is in typescript and I think if I use more of the user data functions etc I would also probably default to wanting to use the built-in methods and definitely for broadcasting since even though I don't use typescript vscode will show me the typehints. I can always slowly learn to effectively use it, but got a bit irritated in a nuxt project where I had to typehint nested return objects and the stupid thing kept bitching when I then try use the child object in the for loop even though I thought the interfaces were connected proper, anyhow I will learn but for now I just slapped
@ts-ignoreon and said fuck it.I guess it is the same if someone names expected params nicely but if Dhive was vanilla I don't think I would know the expected return at a glance?
Doesn't stop me from logging it to be sure and dissecting return values to see how to continue with the data I receive :P
I guess all that to say , yes I can definitely just go full vanilla but I do like the safety net which Dhive acts as while I get more comfortable dealing with chain data. !PIZZA !LOLZ
lolztoken.com
They're both Paris sites.
Credit: dyson-the-booper
@beggars, I sent you an $LOLZ on behalf of @penderis
Use the !LOL or !LOLZ command to share a joke and an $LOLZ
(1/2)
I gifted $PIZZA slices here:
penderis tipped nickydee (x1)
penderis tipped beggars (x1)
@penderis(1/10) tipped @catleen (x1)
penderis tipped rufans (x1)
penderis tipped eturnerx (x1)
penderis tipped mypathtofire (x1)
Please vote for pizza.witness!
Thank you for sharing this post on HIVE!
Your content got selected by our fellow curator priyanarc & you received a little thank you upvote from our non-profit curation initiative. Your post will be featured in one of our recurring curation compilations which is aiming to offer you a stage to widen your audience within the DIY scene of Hive.
Next time make sure to post / cross-post your creation within the DIYHub community on HIVE and you will receive a higher upvote!
Stay creative & hive on!
Dear @penderis,
Your support for the current Hive Authentication Services proposal (#194) is much appreciated but it will expire in a few days!
May I ask you to review and support the new proposal (https://peakd.com/me/proposals/240) so I can continue to improve and maintain this service?
You can support the new proposal (#240) on Peakd, Ecency, Hive.blog or using HiveSigner.
Thank you!
Is this java?
It is Javascript, both in the Node.js environment and browser. !PIZZA