AioHiveBot, minor milestone: Integrated support for hive-engine

Although it is just a minor milestone, it took quite a bit of time and refactoring to get it right, because I don't want hive-engine to be the only layer-2 that aiohivebot supports up to the sidechain level. In fact, the project so far went from 28 hours of total work spent on the project to 41, just to get things working the way that I have trust in the fact that I'm not going to have to do major refactoring if I'm going to add other side chains to the mix (even if my knowledge about other L2s is almost zero).
The aiohivebot code ( available on github and pypi ) now supports both setting event handlers on hive-engine blockchain events, and querying the hive-engine public-API nodes with JSON-RPC requests.
hive-engine support off by default
Because eventhough aiohivebot balances API load between nodes. we still don't want everybodies bot ot layer-2 backend using aiohivebot to add to the load of the hive-engine public API nodes, hive-engine support is off by default.
The refactored design allows you to turn on layer-2 blockchain monitoring for all required L2s, what at this moment in time is just Hive-Engine.
from aiohivebot import BaseBot
class MyBot(BaseBot):
"""Example of an aiohivebot python bot without real utility"""
def __init__(self):
super().__init__(enable_layer2=["engine"])
async def engine_l2_node_status(
self,
node_uri,
error_percentage,
latency,
ok_rate,
error_rate,
block_rate):
print(
"STATUS:",node_uri,
"error percentage =", int(100*error_percentage)/100,
"latency= ", int(100*latency)/100,
"ok=", int(100*ok_rate)/100,
"req/min, errors=", int(100*error_rate)/100,
"req/min, blocks=", int(100*block_rate)/100,
"blocks/min" )
Notice the enable_layer2 line? That line tells aiohivebot to, next to the HIVE public API nodes also start a client collection for the hive-engine public API nodes.
In this code example we define one callback method, engine_l2_node_status. This callback method is equivalent to the node_status method for HIVE public API nodes. It gets called roughly every 15 minutes for each of the konow HIVE-engine API nodes and reports some basic node health stats.
In normal operations you won't need these stats and auihivebot will take care of not using flaky or high latency nodes under the hood.
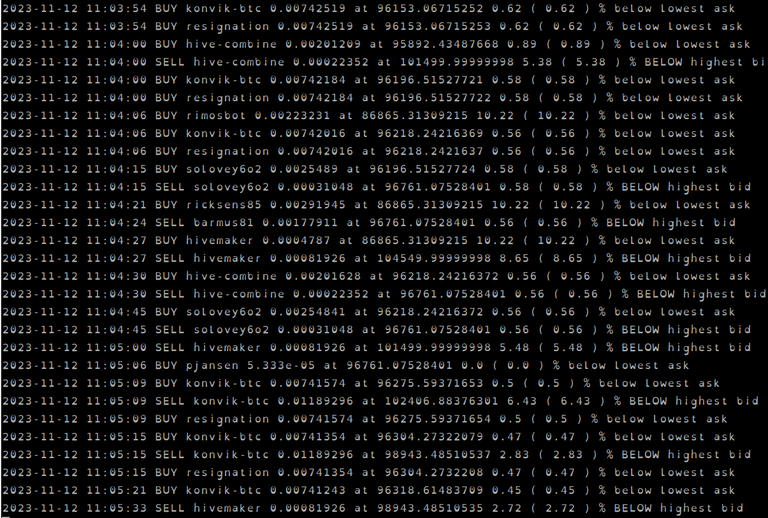
But lets for fun look at the output of running this code for 20 minutes

We see all but one HIVE-engine API nodes is working flawlesly. Only ctpmain.com seems to be down. Completely down. The engine.rishipanthee.com node , at 195 msec seemed to have a somewhat higher request latency than the other nodes that were all between 33 msec and 49 msec. Looking at the blocks per minute we see that aiohivebot does its job of balancing the load of block queries between the nodes. Not perfectly, but good enough.
Hive-engine events without the side-chain
Depending on your needs it might be possible that you don't actually need HIVE-engine API nodes.
Afterall, much of the stuff happens on the main chain using custom_json operations.
Or you might in some cases want both. HIVE-engine nodes for completeness and for querying the tables, and HIVE API node events for the slightly lower latency.
The below code uses just the HIVE public API nodes. It prints whenever someone wants to buy SWAP.BTC on the hive-engine market based on custom_json events.
class MyBot(BaseBot):
"""Example of an aiohivebot python bot without real utility"""
def __init__(self):
super().__init__()
async def engine_market_buy(self, required_auths, required_posting_auths, body):
if body["symbol"] == "SWAP.BTC":
sender = (required_posting_auths + required_auths)[0]
quantity = body["quantity"]
price = body["price"]
print(sender,"wants to buy", quantity, "at a price of", price)
And with the side chain.
The same functionality can be implemented using the HIVE-engine public API nodes.
class MyBot(BaseBot):
"""Example of an aiohivebot python bot without real utility"""
def __init__(self):
super().__init__(enable_layer2=["engine"])
async def engine_l2_market_buy(self, sender, body):
if body["symbol"] == "SWAP.BTC":
quantity = body["quantity"]
price = body["price"]
print(sender,"wants to buy", quantity, "at a price of", price)
Notice the extra _l2 in the method names. We use this to distinguish between processing layer two nfo from custom_json events comming from the main chain, and processing L2 blockchain events.
JSON-RPC queries on hive-engine
Now lets look at what we can do with the actual Hive-engine API. We will create a handler for Hive-engine blocks that doesn't actually handle any of the block data, but instead queries the metrics table of the market contract for the lowest ask and highers bid in the SWAP.BTC market.
class MyBot(BaseBot):
"""Example of an aiohivebot python bot without real utility"""
def __init__(self):
super().__init__(enable_layer2=["engine"])
self.count = 0
self.old_bid = 0.0
self.new_bid = 0.0
self.old_ask = float('inf')
self.new_ask = float('inf')
async def engine_l2_block(self):
self.old_ask = self.new_ask
self.old_bid = self.new_bid
info = await self.l2.engine.contracts.market.metrics.findOne(symbol="SWAP.BTC")
self.new_ask = float(info['lowestAsk'])
self.new_bid = float(info["highestBid"])
See how the query is structured? We invoke the findOne method specifying the symbol that we are interested in. Note that market and metrics are part of the designation of the findOne method, making the API a bit more friendly than if we had to build a complex argument list for findOne.
In the code above we continiously keep track of teh lowest ask and highest bid.
Puting things together
Now lets put things together and make a little useless bot that prints some market action info.
class MyBot(BaseBot):
"""Example of an aiohivebot python bot without real utility"""
def __init__(self):
super().__init__(enable_layer2=["engine"])
self.count = 0
self.old_bid = 0.0
self.new_bid = 0.0
self.old_ask = float('inf')
self.new_ask = float('inf')
async def engine_l2_block(self):
self.old_ask = self.new_ask
self.old_bid = self.new_bid
info = await self.l2.engine.contracts.market.metrics.findOne(symbol="SWAP.BTC")
self.new_ask = float(info['lowestAsk'])
self.new_bid = float(info["highestBid"])
async def engine_market_buy(self,
required_auths,
required_posting_auths,
body,
blockno,
timestamp):
"""Hive Engine custom json action for market buy"""
if body["symbol"] == "SWAP.BTC" and self.old_ask > 0.0:
bid = float(body["price"])
quantity = float(body["quantity"])
relbid1 = int(10000*(self.old_ask - bid) / self.old_ask)/100
relbid2 = int(10000*(self.new_ask - bid) / self.new_ask)/100
if relbid2 >= 0.0:
print(timestamp, "BUY", (required_posting_auths + required_auths)[0],
quantity, "at", bid, relbid2, "(", relbid1, ") % below lowest ask")
else:
print(timestamp, "BUY", (required_posting_auths + required_auths)[0],
quantity, "at", bid, -relbid2, "(", -relbid1, ") % ABOVE lowest ask")
async def engine_market_sell(self,
required_auths,
required_posting_auths,
body,
timestamp):
"""Hive Engine custom json action for market sell"""
if body["symbol"] == "SWAP.BTC" and self.old_bid >0.0:
ask = float(body["price"])
quantity = float(body["quantity"])
relask1 = int(10000*(self.old_bid - ask) / self.old_bid)/100
relask2 = int(10000*(self.new_bid - ask) / self.new_bid)/100
if relask2 >= 0.0:
print(timestamp, "SELL", (required_posting_auths + required_auths)[0],
quantity, "at", ask, relask2,"(", relask1, ") % above highest bid")
else:
print(timestamp, "SELL", (required_posting_auths + required_auths)[0],
quantity, "at", ask, -relask2,"(", -relask1, ") % BELOW highest bid")
In this bot script we query the HIVE-engine public API nodes at every new block so we can update the latest values for bid and ask. We choose to then follow the HIVE custom_json events as source for new bids and asks being submitted to hive-engine, that we compare to the numvers we have available.
Let's have q quick ook at some of the output.
What's next?
While I would like to integrate support for other layer 2 side chains, I'm currently lacking good leads as where to start. I have very little insights into the API infrastructure of these other side-chains, and puting substantial hours into looking at the code of project like the @spknetwork to see if and how I could or should integrate support seems like too much of a time sink right now. I've put them close to the bottom of my priority list. I'm very much open to pull requests though. If you are interested in adding a L2 support, have a look at the code in the l2 dir, it is very doable to add another L2 to the library if you have some insights into the API landscape of that L2 (I currently don't myself).
The first big milesone on the roadmap right now are signed operations.
Right now my todo list for aiohivebot looks as follows:
- Add signed operations support
- Port the Hive Archeology bot to aiohivebot
- Add an example (plus personal use) frontend to the Hive Archeology bot
- Make a new Hive Archeology docker image
- Integrate coinZdense and coinZdense piggyback mode
- Explore and add support for other decentralized L2
- Look at supporting image hoster signed uploads
- Focus exclusively on coinZdense features and base maintenance and bug fixes.
Available for projects
If you think my skills and knowledge could be usefull for your project, I will be available for contract work again for up to 20 hours a week starting next January.
My hourly rate depends on the type of activity (Python dev, C++ dev or data analysis), wether the project at hand will be open source or not, and if you want to sponsor my pet project coinZdense that aims to create a multi-language programming library for post-quantum signing and least authority subkey management.
| Activity | Hourly rate | Open source discount | Minimal hours | Maximum hours |
|---|---|---|---|---|
| C++ development | 150 $HBD | 30 $HBD | 4 | - |
| Python development | 140 $HBD | 30 $HBD | 4 | - |
| Data analysis (python/pandas) | 120 $HBD | - | 2 | - |
| Sponsored coinZdense work | 50 $HBD | - | 0 | - |
| Paired up coinZdense work | 25 $HBD | - | 1 | 2x contract h |
Development work on open-source project get a 30 $HBD discount on my hourly rates.
Next to contract work, you can also become a sponsor of my coinZdense project.
Note that if you pair up to two coinZdense sponsor hours with a contract hour, you can sponsor twice the amount of hours to the coinZdense project.
If you wish to pay for my services or sponsor my project with other coins than $HBD, all rates are slightly higher (same rates, but in Euro or euro equivalent value at transaction time). I welcome payments in Euro (through paypall), $HIVE, $QRL $ZEC, $LTC, $DOGE, $BCH, $ETH or $BTC/lightning.
If instead of hourly rates you want a fixed project price, I'm not offering that, but there are options I can offer to attenuate cost risks if the specs are close to fully defined at project start. It's a +20/-20/-50/-80 setup. Let me give an example. Say you have a decently defined project that I estimate will take me 60 hours. I could for example offer you two options:
| hour | fixed rate | attenuated risk rate |
|---|---|---|
| 1 .. 50 | 100% | 120 % |
| 51 .. 75 | 100% | 80% |
| 75 .. 125 | 100% | 50% |
| > 125 | 100% | 20% |
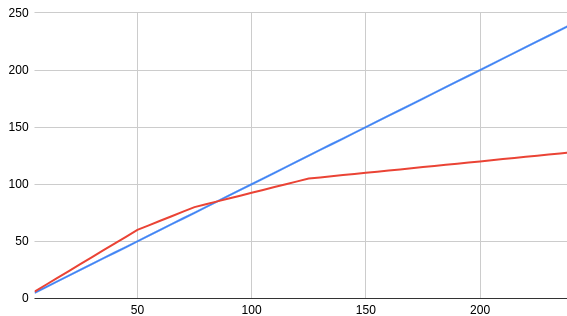
Note that this is just an example, but it illustrates my take on providing you with the option to attenuate project cost risks. There is no fixed price, but still a pretty solid attenuation of your financial risk and a strong incentive for me to not go too much above planning.
Drop me a mail or DM me on X if you are interested in my services. I'm not on discord very often, but if need be, you can find me here on discors too.
Contact: coin<at>z-den.se
The reason for the high latency on my node is due to the fact you were testing in NL, and the node is hosted in west coast USA, takes a little bit for packets to travel that far.
Some advice: Can you throw some compression headers in at this spot: https://github.com/pibara/aiohivebot/blob/main/aiohivebot/core.py#L39 to make sure the data is compressed(unless httpx adds them in automatically, I'm not too sure with python, worth researching).
Also, rather than including the
/contractsand/blockchainpaths, you could actually put them in the method of requests like so:A post of that to just https://engine.rishipanthee.com will yield you with the response you were looking for. This makes it quite handy when using JSONRPC2.0 batches to send out multiple queries in the same http call. Not using this method meant that you can't send both a contracts and a blockchain rpc request in the same http call.
I haven't seen any query that might be using high offset(ex get all nfts owned by a user or get all holders of a token) in your codebase(unless the goal is for the users to do that themselves), but if you add them in, please don't use high offsets to do so, here's a message that I sent on discord:
"""
spent some time looking into whta caused my node to go down yesterday(I think, maybe thrusday, been a busy week). Anyways, looking thru my logs, I saw a ton of requets with really high offsets. It's possibly to rewrite these queries to make them more efficent, so please take some time to do so. Some advice, keep track of the last _id value recieved, and look for entries that have an id greator than that rather than using offsets. It helps a ton. So for example(some js code):
With an offset of 0, we can achieve the same result as increasing the offset while not eating up ram on the nodes.
If you have any apps that rely on high offsets to find everything, please update asap, I will eventually reduce the max offset on my node
"""
High offsets are bad for mongo since they eat up ram, so lets try and avoid that.
Overall, thanks for making this, I don't use python too much other than when needed, but good to see more choices in the ecosystem.