Minor updates to HE-AWM and recipe for LVM based Snapshots
(been a long time since I had put some status of my participation as a witness, apologies for the absence in this regard, although most of you may well know I have been around)
To start, let me update you about some fixes on the monitor that helped me under certain (single-node) circumstances. It is also a proven fact that it has been working quite great for the effort I have put into it. So, a quick win for me.
HE-AWM 1.2.2

Most of the changes are to ensure better stability and protections against log decisions. The added waiting time on the script start allowed for when the node had to be restarted and if for some reason, some nodes would take time to respond or you ended up in a fork, avoid reacting to that.
Extra logic added to how much log information is available to make decisions also avoided enabling the witness unnecessarily (even if afterward it would disable it by correctly detecting that it would not be in sync).
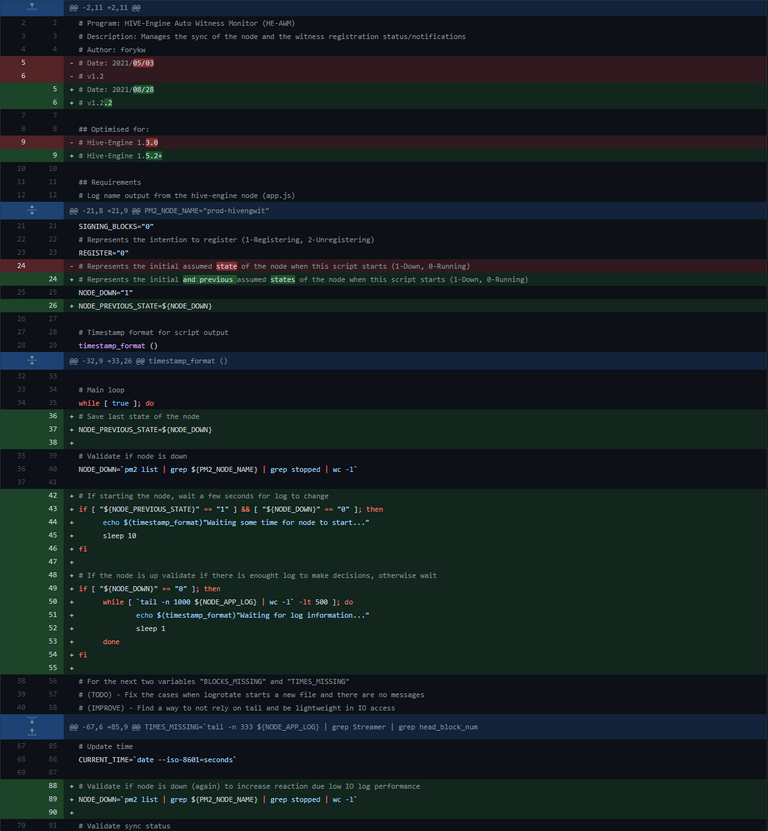
Rest assured, extensively tested under many situations over HE 1.5.2 node code.
Customizations to HE local node code
(these are NOT official changes and mostly represent experimentations from my end that I saw not causing network stability problems)
During the several weeks, I have been running the witness I have come to several situations, either because of the distance to many other Hive nodes or because of normal hardware/software complications. These made me research and test some of the built-in variables that make decisions towards the witnessing.
I wish to be transparent about why I am using these, even if diverging from the actual published code, although proven to be beneficial in my case. If proven to be useful for others, then I will submit a merge request, although I would be inclined for these to be part of a config file as they don't change the consensus/governance.
These are related to the plugins/Streamer.js that processes most of the node synchronization activities. And first having a look at those changes:
it diff Streamer.js
diff --git a/plugins/Streamer.js b/plugins/Streamer.js
index 60da1d0..2df1be6 100644
--- a/plugins/Streamer.js
+++ b/plugins/Streamer.js
@@ -23,7 +23,7 @@ class ForkException {
let currentHiveBlock = 0;
let hiveHeadBlockNumber = 0;
let stopStream = false;
-const antiForkBufferMaxSize = 2;
+const antiForkBufferMaxSize = 5;
const buffer = new Queue(antiForkBufferMaxSize);
let chainIdentifier = '';
let blockStreamerHandler = null;
@@ -31,7 +31,7 @@ let updaterGlobalPropsHandler = null;
let lastBlockSentToBlockchain = 0;
// For block prefetch mechanism
-const maxQps = 1;
+const maxQps = 3;
let capacity = 0;
let totalInFlightRequests = 0;
const inFlightRequests = {};
@@ -386,7 +386,7 @@ const throttledGetBlock = async (blockNumber) => {
// start at index 1, and rotate.
-const lookaheadBufferSize = 100;
+const lookaheadBufferSize = 10;
let lookaheadStartIndex = 0;
let lookaheadStartBlock = currentHiveBlock;
let blockLookaheadBuffer = Array(lookaheadBufferSize);
From top to down...
antiForkBufferMaxSizechanged from 2 to 5 allowed more stability against forksmaxQpsincreased from 1 to 3, a dirty fix to the fact that I am very far away (ping wise) from many HIVE nodes, and by allowing more connections, I can increase the possibility of faster synchronizations.lookaheadBufferSizereduced from 100 to 10, to minimize wasting time on a bigger buffer, providing the assumption that the node should be in sync all the time anyway, hence making this number mostly useful when the node is NOT in sync.
Disclaimer: This is my interpretation of what I have understood about the code. Any misinterpretation, please educate me.
LVM Snapshots?
Yep, some have done snapshot implementations (at the filesystem level) of zfs, others btrfs, of the MongoDB database folder in order to quickly recover from issues, when required. I have opted for showing a different way.
# df -h /var/lib/mongodb
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/mongovg-mongolv 146G 38G 101G 28% /var/lib/mongodb
Currently, with the DB size reaching 38GBs in size, it becomes very heavy to restore the DB from a file (there's added CPU/RAM needed to import the DB). These backups should still be done but if done by many, either using a secondary node or for the ones that can't accommodate that, doing it less frequently can still be a viable option, especially if you don't want to depend on others (or the time to download a dump will just increase the restore time).
Since I am an old LVM person (from AIX), I have decided to procrastinate a bit about that era. LVM is an extra simplification logical layer that joins block access IO with typical resiliency/flexibility features essential to filesystems, usually provided by hardware. Allowing you to detach from filesystem features, giving you great flexibility while being OS/filesystem agnostic.
Pre-requisites
It's important to understand how LVM works and that you need to be aware of what to monitor, although currently there are already some nice features that provide you with some "comfort" of not carrying.
Quick HowTo on LVM
VG (Volume Group)
LV (Logical Volume)
PV (Physical Volume)
VGs contain at least one PV and within VGs you can create many LVs. LVs can span, stripe, or mirror across many PVs. There are also cached and thin-provisioning LV-type available features. If you like this, build a VM and play with it is my recommendation. You will love it!
To "prepare" a PV to be added or used for a VG you just issue pvcreate /dev/sdX for example. Then simply add that PV (that will show in pvscan command as free) to an existing VG with vgextend <VG_name> <PV_name>. You can even add multiple PVs in one go... Then you are ready to create the first LV with something like lvcreate -L 10G <VG_name> -n <LV_name>. Then you can create a filesystem on top of it with mkfs.<FS_type> /dev/<VG_name>/<LV_name> and then mount it wherever you need it with mount /dev/<VG_name>/<LV_name> /<path_to_mount>
For our MongoDB Filesystem
First, you need an LV that is big enough to house your MongoDB filesystem, and in extra to that, some more free space (under the same VG) to create snapshots. The snapshot LVs if created daily, need only to be big enough to allocate the changes or data growth for each of the snapshots you have for as much time you wish them to be valid. Every time you do another snapshot because the changes are done via CoW (copy on write) on the original data, it will be recording more space on each new snapshot LV you create (as opposed to a filesystem level, which will use metadata to differentiate data changes).
The disadvantage of LVM snapshots, in this case, is the extra IO and space needed the more snapshots you decide to maintain. But for DBs this is actually better because usually the same files are being updated and from a filesystem level point of view, you will have the same problem of LVM snapshots.
Changes at the block level thought might (depending on the size of the files) be much more efficient for growing databases. When comparing block-level snapshots to filesystem-based ones, it matters the way the filesystem allocates or changes data blocks. It's a long topic I don't wanna discuss right now.
Just pointing out that alike zfs, LVM snapshots are also possible to be transferable (everything will go with the filesystem and can be restored via dd into a partition for example).
Example
So, in my case, I have a set of 6 virtual disks, 3 for holding the DB filesystem and then another 3 for the snapshots. The advantage of LVM here is that you can decide to change the layout at any time... for example, instead of a 3 disk stripe like I am doing, you can decide for a 6 stripe with less-used per disk, but then use the full parallelization of all the 6 drives. It's all about how you wish IO to compete.
Without further delay... here is the script example! (needs to run as root)
# cat create_snapshot.sh
#!/bin/bash
## To get the day number of each year
DAY=`date +%j`
## To unregister the witness so you don't miss blocks
su -l <USER> -c "cd /path_to_he_node_deployment; node witness_action.js unregister"
sleep 1
## Stop the NodeJS of your witness
su -l <USER> -c "pm2 stop <pm2_process_name>"
## (assumes you have nothing else using the DB) Stop the MongoDB
systemctl stop mongod
## Take a peek of how the current snapshots look if if you have any already
lvs
## Create an 1GB (-L) LV for snapshot (-s) of the mongolv LV striped into 3 (-i 3) physical devices (RAID0) with the name "mongolv_snap${DAY}"
lvcreate -s -L 1G -i 3 -n mongolv_snap${DAY} /dev/mongovg/mongolv
## Take another peek of how it looks after creating the snapshot
lvs
## Start the MongoDB
systemctl start mongod
## Wait 3 seconds for the DB to "start" (this might need to be adjusted depending on VM performance)
sleep 3
## Start the NodeJS of your witness again
su -l <USER> -c "pm2 start <pm2_process_name>"
## If you use a monitor script like me, such as the HE-AWM, it will after being synchronized, register the witness again. Otherwise you will need to wait for being in sync and then issue: su -l <USER> -c "cd /path_to_he_node_deployment; node witness_action.js register"
Also, to make your life easier, the LV can auto-extend if required... although, you still need to monitor for VG free space (pvscan will show you that), aka unallocated space to LVs inside your VG.
# pvscan
PV /dev/sdd VG mongovg lvm2 [<50.00 GiB / 336.00 MiB free]
PV /dev/sde VG mongovg lvm2 [<50.00 GiB / 336.00 MiB free]
PV /dev/sdf VG mongovg lvm2 [<50.00 GiB / 336.00 MiB free]
PV /dev/sdg VG mongovg lvm2 [<50.00 GiB / <49.33 GiB free]
PV /dev/sdh VG mongovg lvm2 [<50.00 GiB / <49.33 GiB free]
PV /dev/sdi VG mongovg lvm2 [<50.00 GiB / <49.33 GiB free]
PV /dev/sda5 VG vgubuntu lvm2 [<19.50 GiB / 0 free]
PV /dev/sdb VG vgubuntu lvm2 [<50.00 GiB / 0 free]
PV /dev/sdc VG vgubuntu lvm2 [<50.00 GiB / 28.00 MiB free]
Total: 9 [419.46 GiB] / in use: 9 [419.46 GiB] / in no VG: 0 [0 ]
The defaults are 100% and 20%. But I have changed that to 90/10. It's important if when the time to extend the LV vs the time to write (committing) the DB entry will create a situation that will fail to update the DB.
# cat /etc/lvm/lvm.conf |grep snapshot_auto |grep -v \#
snapshot_autoextend_threshold = 90
snapshot_autoextend_percent = 10
I would advise to output the stdout and stderr to a log file in order to monitor later the status of this per whatever period you wish (in the case above is a per day thing that can be initiated via crontab).
Then because you can't keep snapshots forever, you should have another script to recycle space over time. I will leave that for the next post.
Google Drive 15GBs is ending...
To finalize, the solution I provided here will be ending from my side as I will not be able (for now) to sustain the costs of increasing the @forkyishere google drive space.
If it helped at least 1 person, I am already happy. Plus, the experience gained from doing it, which is the best part of it in my view (while being supported here).
I will soon disable it and leave there the last one that fits. At least it will be one place to get an old database backup if needed.
🗳 Vote for Hive-Engine Witnesses here!!!
If you like this work, consider supporting (@atexoras.witness) as a witness. I am going to continue this work as much as I am permitted to and also because it's really great fun for a geek like me! 😋😎
What type of storage requirements does LVM snapshots have? And I assume this means that I'd have to snapshot ALL of my mongo collections, including the history on my server that I use to make snapshots?
LVM can use any block level device (anything inside /dev/ like HDD, SSD, NVMes, etc). I will add some quick info about how to create these on the post later today.
But LVM snapshots are per LV basis, so because usually you have a LV (a) per FS, when you snapshot that LV, what is happening, is you are creating another LV (b) in the same VG where all the modified blocks of the original LV (a) are being copied into the snapshot LV (b).
So if you need to separate at MongoDB level, you might want to have different filesystems/LVs for each of the collections you have, and then either also separate using multiple mongo instances (I would find it easier), or specific different folders for the collection so that you can then use them a separate filesystems and be able to use different LV snapshots for each of them.
The great part about having everything on one place is simplicity, but space use might be a problem if you don't want to snapshot everything, yep. Hence separating per instance/collection would be necessary.
I will update more by the end of my day.
So I'd need another drive with an equal amount of space? (I'm not really good with server management other than exactly what I need done so I don't know all these terms haha)
View more
@atexoras! This post has been manually curated by the $PIZZA Token team!
Learn more about $PIZZA Token at hive.pizza. Enjoy a slice of $PIZZA on us!
Updated post with some more extra information to facilitate reading and from feedback received.